Apache Kafka:为“无缝系统”提供异步消息支持
Apache Kafka 是最流行的开源消息代理之一。它已经成为了大数据操作的重要组成部分,你能够在几乎所有的微服务环境中找到它。本文对 Apache Kafka 进行了简要介绍,并提供了一个案例来展示它的使用方式。

你有没有想过,电子商务平台是如何在处理巨大的流量时,做到不会卡顿的呢?有没有想过,OTT 平台是如何在同时向数百万用户交付内容时,做到平稳运行的呢?其实,关键就在于它们的分布式架构。
采用分布式架构设计的系统由多个功能组件组成。这些功能组件通常分布在多个机器上,它们通过网络,异步地交换消息,从而实现相互协作。正是由于异步消息的存在,组件之间才能实现可伸缩、无阻塞的通信,整个系统才能够平稳运行。
异步消息
异步消息的常见特性有:
- 消息的 生产者 和 消费者 都不知道彼此的存在。它们在不知道对方的情况下,加入和离开系统。
- 消息 代理 充当了生产者和消费者之间的中介。
- 生产者把每条消息,都与一个“ 主题 ”相关联。主题是一个简单的字符串。
- 生产者可以在多个主题上发送消息,不同的生产者也可以在同一主题上发送消息。
- 消费者向代理订阅一个或多个主题的消息。
- 生产者只将消息发送给代理,而不发送给消费者。
- 代理会把消息发送给订阅该主题的所有消费者。
- 代理将消息传递给针对该主题注册的所有消费者。
- 生产者并不期望得到消费者的任何回应。换句话说,生产者和消费者不会相互阻塞。
市场上的消息代理有很多,而 Apache Kafka 是其中最受欢迎的之一。
Apache Kafka
Apache Kafka 是一个支持流式处理的、开源的分布式消息系统,它由 Apache 软件基金会开发。在架构上,它是多个代理组成的集群,这些代理间通过 Apache ZooKeeper 服务来协调。在接收、持久化和发送消息时,这些代理分担集群上的负载。
分区
Kafka 将消息写入称为“ 分区 ”的桶中。一个特定分区只保存一个主题上的消息。例如,Kafka 会把 heartbeats 主题上的消息写入名为 heartbeats-0 的分区(假设它是个单分区主题),这个过程和生产者无关。
不过,为了利用 Kafka 集群所提供的并行处理能力,管理员通常会为指定主题创建多个分区。举个例子,假设管理员为 heartbeats 主题创建了三个分区,Kafka 会将它们分别命名为 heartbeats-0、heartbeats-1 和 heartbeats-2。Kafka 会以某种方式,把消息分配到这三个分区中,并使它们均匀分布。
还有另一种可能的情况,生产者将每条消息与一个 消息键 相关联。例如,同样都是在 heartbeats 主题上发送消息,有个组件使用 C1 作为消息键,另一个则使用 C2。在这种情况下,Kafka 会确保,在一个主题中,带有相同消息键的消息,总是会被写入到同一个分区。不过,在一个分区中,消息的消息键却不一定相同。下面的图 2 显示了消息在不同分区中的一种可能分布。

领导者和同步副本
Kafka 在(由多个代理组成的)集群中维护了多个分区。其中,负责维护分区的那个代理被称为“ 领导者 ”。只有领导者能够在它的分区上接收和发送消息。
可是,万一分区的领导者发生故障了,又该怎么办呢?为了确保业务连续性,每个领导者(代理)都会把它的分区复制到其他代理上。此时,这些其他代理就称为该分区的 同步副本 (ISR)。一旦分区的领导者发生故障,ZooKeeper 就会发起一次选举,把选中的那个同步副本任命为新的领导者。此后,这个新的领导者将承担该分区的消息接受和发送任务。管理员可以指定分区需要维护的同步副本的大小。

消息持久化
代理会将每个分区都映射到一个指定的磁盘文件,从而实现持久化。默认情况下,消息会在磁盘上保留一个星期。当消息写入分区后,它们的内容和顺序就不能更改了。管理员可以配置一些策略,如消息的保留时长、压缩算法等。
消费消息
与大多数其他消息系统不同,Kafka 不会主动将消息发送给消费者。相反,消费者应该监听主题,并主动读取消息。一个消费者可以从某个主题的多个分区中读取消息。多个消费者也可以读取来自同一个分区的消息。Kafka 保证了同一条消息不会被同一个消费者重复读取。
Kafka 中的每个消费者都有一个组 ID。那些组 ID 相同的消费者们共同组成了一个消费者组。通常,为了从 N 个主题分区读取消息,管理员会创建一个包含 N 个消费者的消费者组。这样一来,组内的每个消费者都可以从它的指定分区中读取消息。如果组内的消费者比可用分区还要多,那么多出来的消费者就会处于闲置状态。
在任何情况下,Kafka 都保证:不管组内有多少个消费者,同一条消息只会被该消费者组读取一次。这个架构提供了一致性、高性能、高可扩展性、准实时交付和消息持久性,以及零消息丢失。
安装、运行 Kafka
尽管在理论上,Kafka 集群可以由任意数量的代理组成,但在生产环境中,大多数集群通常由三个或五个代理组成。
在这里,我们将搭建一个单代理集群,对于生产环境来说,它已经够用了。
在浏览器中访问 https://kafka.apache.org/downloads,下载 Kafka 的最新版本。在 Linux 终端中,我们也可以使用下面的命令来下载它:
1 | |
如果需要的话,我们也可以把下载来的档案文件 kafka_2.12-2.8.0.tgz 移动到另一个目录下。解压这个档案,你会得到一个名为 kafka_2.12-2.8.0 的目录,它就是之后我们要设置的 KAFKA_HOME。
打开 KAFKA_HOME/config 目录下的 server.properties 文件,取消注释下面这一行配置:
1 | |
这行配置的作用是让 Kafka 在本机的 9092 端口接收普通文本消息。我们也可以配置 Kafka 通过 安全通道 接收消息,在生产环境中,我们也推荐这么做。
无论集群中有多少个代理,Kafka 都需要 ZooKeeper 来管理和协调它们。即使是单代理集群,也是如此。Kafka 在安装时,会附带安装 ZooKeeper,因此,我们可以在 KAFKA_HOME 目录下,在命令行中使用下面的命令来启动它:
1 | |
当 ZooKeeper 运行起来后,我们就可以在另一个终端中启动 Kafka 了,命令如下:
1 | |
到这里,一个单代理的 Kafka 集群就运行起来了。
验证 Kafka
让我们在 toindex_img-1 主题上尝试下发送和接收消息吧!我们可以使用下面的命令,在创建主题时为它指定分区的个数:
1 | |
上述命令还同时指定了 复制因子 ,它的值不能大于集群中代理的数量。我们使用的是单代理集群,因此,复制因子只能设置为 1。
当主题创建完成后,生产者和消费者就可以在上面交换消息了。Kafka 的发行版内附带了生产者和消费者的命令行工具,供测试时用。
打开第三个终端,运行下面的命令,启动生产者:
1 | |
上述命令显示了一个提示符,我们可以在后面输入简单文本消息。由于我们指定的命令选项,生产者会把 toindex_img-1 上的消息,发送到运行在本机的 9092 端口的 Kafka 中。
打开第四个终端,运行下面的命令,启动消费者:
1 | |
上述命令启动了一个消费者,并指定它连接到本机 9092 端口的 Kafka。它订阅了 toindex_img-1 主题,以读取其中的消息。由于命令行的最后一个选项,这个消费者会从最开头的位置,开始读取该主题的所有消息。
我们注意到,生产者和消费者连接的是同一个代理,访问的是同一个主题,因此,消费者在收到消息后会把消息打印到终端上。
下面,让我们在实际应用场景中,尝试使用 Kafka 吧!
案例
假设有一家叫做 ABC 的公共汽车运输公司,它拥有一支客运车队,往返于全国不同城市之间。由于 ABC 希望实时跟踪每辆客车,以提高其运营质量,因此,它提出了一个基于 Apache Kafka 的解决方案。
首先,ABC 公司为所有公交车都配备了位置追踪设备。然后,它使用 Kafka 建立了一个操作中心,以接收来自数百辆客车的位置更新。它还开发了一个 仪表盘 ,以显示任一时间点所有客车的当前位置。图 5 展示了上述架构:
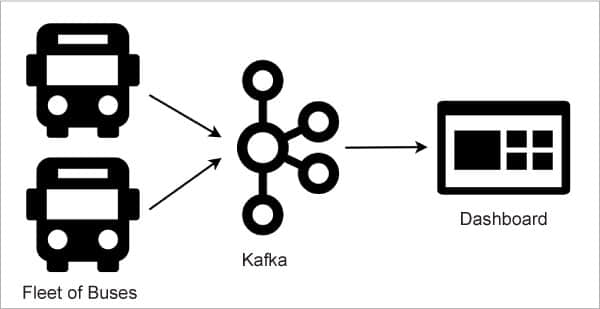
在这种架构下,客车上的设备扮演了消息生产者的角色。它们会周期性地把当前位置发送到 Kafka 的 abc-bus-location 主题上。ABC 公司选择以客车的 行程编号 作为消息键,以处理来自不同客车的消息。例如,对于从 Bengaluru 到 Hubballi 的客车,它的行程编号就会是 BLRHL003,那么在这段旅程中,对于所有来自该客车的消息,它们的消息键都会是 BLRHL003。
仪表盘应用扮演了消息消费者的角色。它在代理上注册了同一个主题 abc-bus-location。如此,这个主题就成为了生产者(客车)和消费者(仪表盘)之间的虚拟通道。
客车上的设备不会期待得到来自仪表盘应用的任何回复。事实上,它们相互之间都不知道对方的存在。得益于这种架构,数百辆客车和操作中心之间实现了非阻塞通信。
实现
假设 ABC 公司想要创建三个分区来维护位置更新。由于我们的开发环境只有一个代理,因此复制因子应设置为 1。
相应地,以下命令创建了符合需求的主题:
1 | |
生产者和消费者应用可以用多种语言编写,如 Java、Scala、Python 和 JavaScript 等。下面几节中的代码展示了它们在 Java 中的编写方式,好让我们有一个初步了解。
Java 生产者
下面的 Fleet 类模拟了在 ABC 公司的 6 辆客车上运行的 Kafka 生产者应用。它会把位置更新发送到指定代理的 abc-bus-location 主题上。请注意,简单起见,主题名称、消息键、消息内容和代理地址等,都在代码里硬编码的。
1 | |
Java 消费者
下面的 Dashboard 类实现了一个 Kafka 消费者应用,运行在 ABC 公司的操作中心。它会监听 abc-bus-location 主题,并且它的消费者组 ID 是 abc-dashboard。当收到消息后,它会立即显示来自客车的详细位置信息。我们本该配置这些详细位置信息,但简单起见,它们也是在代码里硬编码的:
1 | |
依赖
为了编译和运行这些代码,我们需要 JDK 8 及以上版本。看到下面的 pom.xml 文件中的 Maven 依赖了吗?它们会把所需的 Kafka 客户端库下载并添加到类路径中:
1 | |
部署
由于 abc-bus-location 主题在创建时指定了 3 个分区,我们自然就会想要运行 3 个消费者,来让读取位置更新的过程更快一些。为此,我们需要同时在 3 个不同的终端中运行仪表盘。因为所有这 3 个仪表盘都注册在同一个组 ID 下,它们自然就构成了一个消费者组。Kafka 会为每个仪表盘都分配一个特定的分区(来消费)。
当所有仪表盘实例都运行起来后,在另一个终端中启动 Fleet 类。图 6、7、8 展示了仪表盘终端中的控制台示例输出。
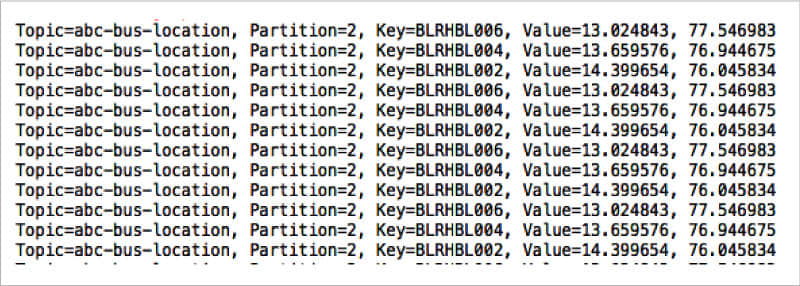
仔细看看控制台消息,我们会发现第一个、第二个和第三个终端中的消费者,正在分别从 partition-2、partition-1 和 partition-0 中读取消息。另外,我们还能发现,消息键为 BLRHBL002、BLRHBL004 和 BLRHBL006 的消息写入了 partition-2,消息键为 BLRHBL005 的消息写入了 partition-1,剩下的消息写入了 partition-0。

使用 Kafka 的好处在于,只要集群设计得当,它就可以水平扩展,从而支持大量客车和数百万条消息。

不止是消息
根据 Kafka 官网上的数据,在《财富》100 强企业中,超过 80% 都在使用 Kafka。它部署在许多垂直行业,如金融服务、娱乐等。虽然 Kafka 起初只是一种简单的消息服务,但它已凭借行业级的流处理能力,成为了大数据生态系统的一环。对于那些喜欢托管解决方案的企业,Confluent 提供了基于云的 Kafka 服务,只需支付订阅费即可。(LCTT 译注:Confluent 是一个基于 Kafka 的商业公司,它提供的 Confluent Kafka 在 Apache Kafka 的基础上,增加了许多企业级特性,被认为是“更完整的 Kafka”。)
via: https://www.opensourceforu.com/2021/11/apache-kafka-asynchronous-messaging-for-seamless-systems/
作者:Krishna Mohan Koyya 选题:lkxed 译者:lkxed 校对:wxy