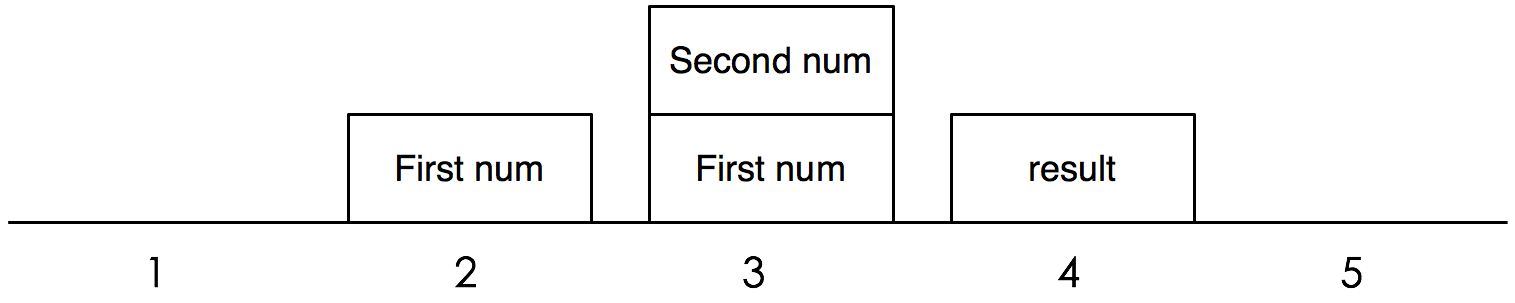
what_to_execute = { "instructions": [("LOAD_VALUE", 0), # the first number ("LOAD_VALUE", 1), # the second number ("ADD_TWO_VALUES", None), ("PRINT_ANSWER", None)], "numbers": [7, 5] }
defSTORE_NAME(self, name): val = self.stack.pop() self.environment[name] = val
defLOAD_NAME(self, name): val = self.environment[name] self.stack.append(val)
defparse_argument(self, instruction, argument, what_to_execute): """ Understand what the argument to each instruction means.""" numbers = ["LOAD_VALUE"] names = ["LOAD_NAME", "STORE_NAME"]
if instruction in numbers: argument = what_to_execute["numbers"][argument] elif instruction in names: argument = what_to_execute["names"][argument]
return argument
defrun_code(self, what_to_execute): instructions = what_to_execute["instructions"] for each_step in instructions: instruction, argument = each_step argument = self.parse_argument(instruction, argument, what_to_execute)
>>> cond.__code__.co_code # the bytecode as raw bytes b'd\x01\x00}\x00\x00|\x00\x00d\x02\x00k\x00\x00r\x16\x00d\x03\x00Sd\x04\x00Sd\x00 \x00S' >>> list(cond.__code__.co_code) # the bytecode as numbers [100,1,0,125,0,0,124,0,0,100,2,0,107,0,0,114,22,0,100,3,0,83, 100,4,0,83,100,0,0,83]
Python 的循环也依赖于跳转。在下面的字节码中,while x < 5这一行产生了和if x < 10几乎一样的字节码。在这两种情况下,解释器都是先执行比较,然后执行POP_JUMP_IF_FALSE来控制下一条执行哪个指令。第四行的最后一条字节码JUMP_ABSOLUT(循环体结束的地方),让解释器返回到循环开始的第 9 条指令处。当 x < 10变为假,POP_JUMP_IF_FALSE会让解释器跳到循环的终止处,第 34 条指令。
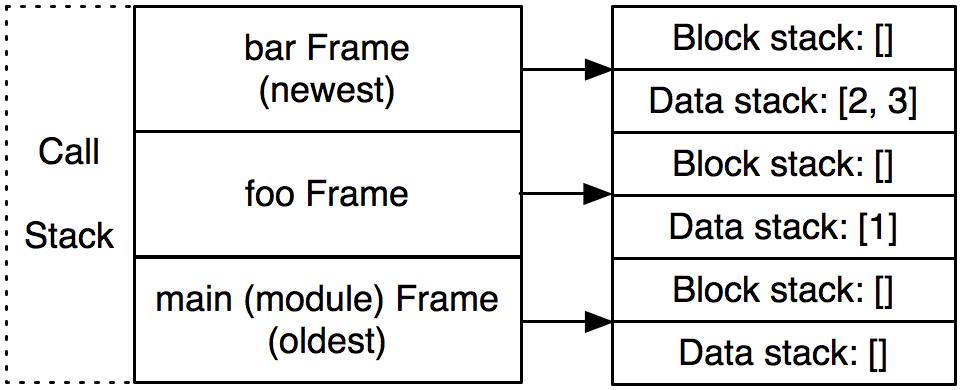
>>>defbar(y): ... z = y + 3# <--- (3) ... and the interpreter is here. ...return z ... >>>deffoo(): ... a = 1 ... b = 2 ...return a + bar(b) # <--- (2) ... which is returning a call to bar ... ... >>>foo() # <--- (1) We're in the middle of a call to foo ... 3
classVirtualMachine(object): def__init__(self): self.frames = [] # The call stack of frames. self.frame = None# The current frame. self.return_value = None self.last_exception = None
defrun_code(self, code, global_names=None, local_names=None): """ An entry point to execute code using the virtual machine.""" frame = self.make_frame(code, global_names=global_names, local_names=local_names) self.run_frame(frame)
classFunction(object): """ Create a realistic function object, defining the things the interpreter expects. """ __slots__ = [ 'func_code', 'func_name', 'func_defaults', 'func_globals', 'func_locals', 'func_dict', 'func_closure', '__name__', '__dict__', '__doc__', '_vm', '_func', ]
def__init__(self, name, code, globs, defaults, closure, vm): """You don't need to follow this closely to understand the interpreter.""" self._vm = vm self.func_code = code self.func_name = self.__name__ = name or code.co_name self.func_defaults = tuple(defaults) self.func_globals = globs self.func_locals = self._vm.frame.f_locals self.__dict__ = {} self.func_closure = closure self.__doc__ = code.co_consts[0] if code.co_consts elseNone
# Sometimes, we need a real Python function. This is for that. kw = { 'argdefs': self.func_defaults, } if closure: kw['closure'] = tuple(make_cell(0) for _ in closure) self._func = types.FunctionType(code, globs, **kw)
def__call__(self, *args, **kwargs): """When calling a Function, make a new frame and run it.""" callargs = inspect.getcallargs(self._func, *args, **kwargs) # Use callargs to provide a mapping of arguments: values to pass into the new # frame. frame = self._vm.make_frame( self.func_code, callargs, self.func_globals, {} ) returnself._vm.run_frame(frame)
defmake_cell(value): """Create a real Python closure and grab a cell.""" # Thanks to Alex Gaynor for help with this bit of twistiness. fn = (lambda x: lambda: x)(value) return fn.__closure__[0]
defpopn(self, n): """Pop a number of values from the value stack. A list of `n` values is returned, the deepest value first. """ if n: ret = self.frame.stack[-n:] self.frame.stack[-n:] = [] return ret else: return []
def parse_byte_and_args(self): f = self.frame opoffset = f.last_instruction byteCode = f.code_obj.co_code[opoffset] f.last_instruction += 1 byte_name = dis.opname[byteCode] if byteCode >= dis.HAVE_ARGUMENT: # index into the bytecode arg = f.code_obj.co_code[f.last_instruction:f.last_instruction+2] f.last_instruction += 2# advance the instruction pointer arg_val = arg[0] + (arg[1] * 256) if byteCode in dis.hasconst: # Look up a constant arg = f.code_obj.co_consts[arg_val] elif byteCode in dis.hasname: # Look up a name arg = f.code_obj.co_names[arg_val] elif byteCode in dis.haslocal: # Look up a local name arg = f.code_obj.co_varnames[arg_val] elif byteCode in dis.hasjrel: # Calculate a relative jump arg = f.last_instruction + arg_val else: arg = arg_val argument = [arg] else: argument = []
defdispatch(self, byte_name, argument): """ Dispatch by bytename to the corresponding methods. Exceptions are caught and set on the virtual machine."""
# When later unwinding the block stack, # we need to keep track of why we are doing it. why = None try: bytecode_fn = getattr(self, 'byte_%s' % byte_name, None) if bytecode_fn isNone: if byte_name.startswith('UNARY_'): self.unaryOperator(byte_name[6:]) elif byte_name.startswith('BINARY_'): self.binaryOperator(byte_name[7:]) else: raise VirtualMachineError( "unsupported bytecode type: %s" % byte_name ) else: why = bytecode_fn(*argument) except: # deal with exceptions encountered while executing the op. self.last_exception = sys.exc_info()[:2] + (None,) why = 'exception'
return why
defrun_frame(self, frame): """Run a frame until it returns (somehow). Exceptions are raised, the return value is returned. """ self.push_frame(frame) whileTrue: byte_name, arguments = self.parse_byte_and_args()
why = self.dispatch(byte_name, arguments)
# Deal with any block management we need to do while why and frame.block_stack: why = self.manage_block_stack(why)
if why: break
self.pop_frame()
if why == 'exception': exc, val, tb = self.last_exception e = exc(val) e.__traceback__ = tb raise e
defunwind_block(self, block): """Unwind the values on the data stack corresponding to a given block.""" if block.type == 'except-handler': # The exception itself is on the stack as type, value, and traceback. offset = 3 else: offset = 0
## Names defbyte_LOAD_NAME(self, name): frame = self.frame if name in frame.f_locals: val = frame.f_locals[name] elif name in frame.f_globals: val = frame.f_globals[name] elif name in frame.f_builtins: val = frame.f_builtins[name] else: raise NameError("name '%s' is not defined" % name) self.push(val)
defbyte_LOAD_FAST(self, name): if name inself.frame.f_locals: val = self.frame.f_locals[name] else: raise UnboundLocalError( "local variable '%s' referenced before assignment" % name ) self.push(val)
defbyte_LOAD_GLOBAL(self, name): f = self.frame if name in f.f_globals: val = f.f_globals[name] elif name in f.f_builtins: val = f.f_builtins[name] else: raise NameError("global name '%s' is not defined" % name) self.push(val)
defbinaryOperator(self, op): x, y = self.popn(2) self.push(self.BINARY_OPERATORS[op](x, y))
COMPARE_OPERATORS = [ operator.lt, operator.le, operator.eq, operator.ne, operator.gt, operator.ge, lambda x, y: x in y, lambda x, y: x notin y, lambda x, y: x is y, lambda x, y: x isnot y, lambda x, y: issubclass(x, Exception) andissubclass(x, y), ]
defbyte_COMPARE_OP(self, opnum): x, y = self.popn(2) self.push(self.COMPARE_OPERATORS[opnum](x, y))
## Attributes and indexing
defbyte_LOAD_ATTR(self, attr): obj = self.pop() val = getattr(obj, attr) self.push(val)