如何在 Linux 中将文件编码转换为 UTF-8
在这篇教程中,我们将解释字符编码的含义,然后给出一些使用命令行工具将使用某种字符编码的文件转化为另一种编码的例子。最后,我们将一起看一看如何在 Linux 下将使用各种字符编码的文件转化为 UTF-8 编码。

你可能已经知道,计算机除了二进制数据,是不会理解和存储字符、数字或者任何人类能够理解的东西的。一个二进制位只有两种可能的值,也就是 0 或 1,真或假,是或否。其它的任何事物,比如字符、数据和图片,必须要以二进制的形式来表现,以供计算机处理。
简单来说,字符编码是一种可以指示电脑来将原始的 0 和 1 解释成实际字符的方式,在这些字符编码中,字符都以一串数字来表示。
字符编码方案有很多种,比如 ASCII、ANCI、Unicode 等等。下面是 ASCII 编码的一个例子。
1 | |
在 Linux 中,命令行工具 iconv 用来将使用一种编码的文本转化为另一种编码。
你可以使用 file 命令,并添加 -i 或 --mime 参数来查看一个文件的字符编码,这个参数可以让程序像下面的例子一样输出字符串的 mime (Multipurpose Internet Mail Extensions) 数据:
1 | |

在 Linux 中查看文件的编码
iconv 工具的使用方法如下:
1 | |
在这里,-f 或 --from-code 表明了输入编码,而 -t 或 --to-encoding 指定了输出编码。
为了列出所有已有编码的字符集,你可以使用以下命令:
1 | |
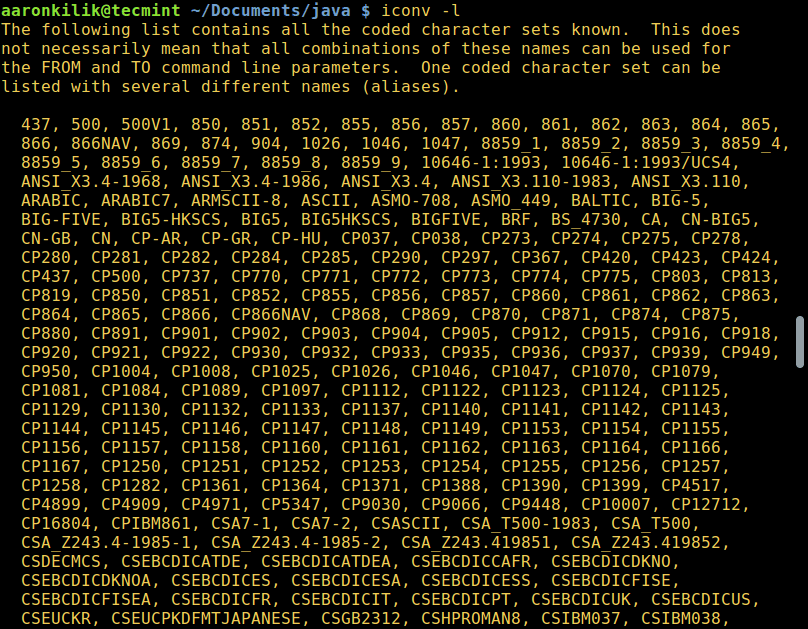
列出所有已有编码字符集
将文件从 ISO-8859-1 编码转换为 UTF-8 编码
下面,我们将学习如何将一种编码方案转换为另一种编码方案。下面的命令将会将 ISO-8859-1 编码转换为 UTF-8 编码。
考虑如下文件 input.file,其中包含这几个字符:
1 | |
我们从查看这个文件的编码开始,然后来查看文件内容。最后,我们可以把所有字符转换为 UTF-8 编码。
在运行 iconv 命令之后,我们可以像下面这样检查输出文件的内容,和它使用的字符编码。
1 | |
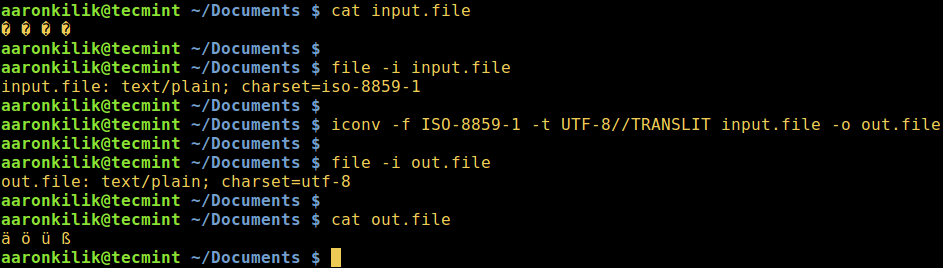
在 Linux 中将 ISO-8859-1 转化为 UTF-8
注意:如果输出编码后面添加了 //IGNORE 字符串,那些不能被转换的字符将不会被转换,并且在转换后,程序会显示一条错误信息。
好,如果字符串 //TRANSLIT 被添加到了上面例子中的输出编码之后 (UTF-8//TRANSLIT),待转换的字符会尽量采用形译原则。也就是说,如果某个字符在输出编码方案中不能被表示的话,它将会被替换为一个形状比较相似的字符。
而且,如果一个字符不在输出编码中,而且不能被形译,它将会在输出文件中被一个问号标记 ? 代替。
将多个文件转换为 UTF-8 编码
回到我们的主题。如果你想将多个文件甚至某目录下所有文件转化为 UTF-8 编码,你可以像下面一样,编写一个简单的 shell 脚本,并将其命名为 encoding.sh:
1 | |
保存文件,然后为它添加可执行权限。在待转换文件 (*.txt) 所在的目录中运行这个脚本。
1 | |
重要事项:你也可以使这个脚本变得更通用,比如转换任意特定的字符编码到另一种编码。为了达到这个目的,你只需要改变 FROM_ENCODING 及 TO_ENCODING 变量的值。别忘了改一下输出文件的文件名 "${file%.txt}.utf8.converted".
若要了解更多信息,可以查看 iconv 的 手册页 。
1 | |
将这篇指南总结一下,理解字符编码的概念、了解如何将一种编码方案转换为另一种,是一个电脑用户处理文本时必须要掌握的知识,程序员更甚。
最后,你可以在下面的评论部分中与我们联系,提出问题或反馈。
via: http://www.tecmint.com/convert-files-to-utf-8-encoding-in-linux/
作者:Aaron Kili 译者:StdioA 校对:wxy