为什么(大多数)高级语言运行效率较慢
在近一两个月中,我多次的和线上线下的朋友讨论了这个话题,所以我干脆直接把它写在博客中,以便以后查阅。
大部分高级语言运行效率较慢的原因通常有两点:
- 没有很好的利用缓存;
- 垃圾回收机制性能消耗高。
但事实上,这两个原因可以归因于:高级语言强烈地鼓励编程人员分配很多的内存。

首先,下文内容主要讨论客户端应用。如果你的程序有 99.9% 的时间都在等待网络 I/O,那么这很可能不是拖慢语言运行效率的原因——优先考虑的问题当然是优化网络。在本文中,我们主要讨论程序在本地执行的速度。
我将选用 C# 语言作为本文的参考语言,其原因有二:首先它是我常用的高级语言;其次如果我使用 Java 语言,许多使用 C# 的朋友会告诉我 C# 不会有这些问题,因为它有值类型(但这是错误的)。
接下来我将会讨论,出于编程习惯编写的代码、使用 普遍编程方法 的代码或使用库或教程中提到的常用代码来编写程序时会发生什么。我对那些使用难搞的办法来解决语言自身毛病以“证明”语言没毛病这事没兴趣,当然你可以和语言抗争来避免它的毛病,但这并不能说明语言本身是没有问题的。
回顾缓存消耗问题
首先我们先来回顾一下合理使用缓存的重要性。下图是基于在 Haswell 架构下内存延迟对 CPU 影响的 数据:
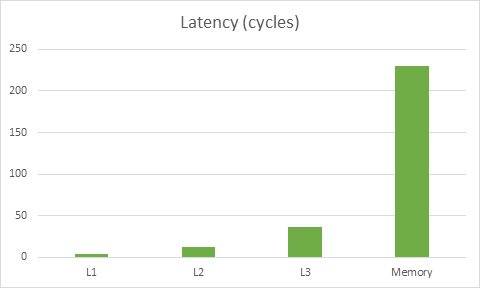
针对这款 CPU 读取内存的延迟,CPU 需要消耗近 230 个运算周期从内存读取数据,同时需要消耗 4 个运算周期来读取 L1 缓冲区。因此错误的去使用缓存可导致运行速度拖慢近 50 倍。还好这并不是最糟糕的——在现代 CPU 中它们能同时地做多种操作,所以当你加载 L1 缓冲区内容的同时这个内容已经进入到了寄存器,因此数据从 L1 缓冲区加载这个过程的性能消耗就被部分或完整的掩盖了起来。
撇开选择合理的算法不谈,不夸张地讲,在性能优化中你要考虑的最主要因素其实是缓存未命中。当你能够有效的访问一个数据时候,你才需要考虑优化你的每个具体的操作。与缓存未命中的问题相比,那些次要的低效问题对运行速度并没有什么过多的影响。
这对于编程语言的设计者来说是一个好消息!你都不必去编写一个最高效的编译器,你可以完全摆脱一些额外的开销(比如:数组边界检查),你只需要专注怎么设计语言能高效地编写代码来访问数据,而不用担心与 C 语言代码比较运行速度。
为什么 C# 存在缓存未命中问题
坦率地讲 C# 在设计时就没打算在现代缓存中实现高效运行。我又一次提到程序语言设计的局限性以及其带给程序员无法编写高效的代码的“压力”。大部分的理论上的解决方法其实都非常的不便,这里我说的是那些编程语言“希望”你这样编写的惯用写法。
C# 最基本的问题是对 基础值类型 低下的支持性。其大部分的数据结构都是“内置”在语言内定义的(例如:栈,或其他内置对象)。但这些具有帮助性的内置结构体有一些大问题,以至于更像是创可贴而不是解决方案。
- 你得把自己定义的结构体类型在最先声明——这意味着你如果需要用到这个类型作为堆分配,那么所有的结构体都会被堆分配。你也可以使用一些类包装器来打包你的结构体和其中的成员变量,但这十分的痛苦。如果类和结构体可以相同的方式声明,并且可根据具体情况来使用,这将是更好的。当数据可以作为值地存储在自定义的栈中,当这个数据需要被堆分配时你就可以将其定义为一个对象,比如 C++ 就是这样工作的。因为只有少数的内容需要被堆分配,所以我们不鼓励所有的内容都被定义为对象类型。
- 引用 值被苛刻的限制。你可以将一个引用值传给函数,但只能这样。你不能直接引用
List<int>中的元素,你必须先把所有的引用和索引全部存储下来。你不能直接取得指向栈、对象中的变量(或其他变量)的指针。你只能把它们复制一份,除了将它们传给一个函数(使用引用的方式)。当然这也是可以理解的。如果类型安全是一个先驱条件,灵活的引用变量和保证类型安全这两项要同时支持太难了(虽然不是不可能)。这些限制背后的理念并不能改变限制存在的事实。 - 固定大小的缓冲区 不支持自定义类型,而且还必须使用
unsafe关键字。 - 有限的“数组切片”功能。虽然有提供
ArraySegment类,但并没有人会使用它,这意味着如果只需要传递数组的一部分,你必须去创建一个IEnumerable对象,也就意味着要分配大小(包装)。就算接口接受ArraySegment对象作为参数,也是不够的——你只能用普通数组,而不能用List<T>,也不能用 栈数组 等等。
最重要的是,除了非常简单的情况之外,C# 非常惯用堆分配。如果所有的数据都被堆分配,这意味着被访问时会造成缓存未命中(从你无法决定对象是如何在堆中存储开始)。所以当 C++ 程序面临着如何有效的组织数据在缓存中的存储这个挑战时,C# 则鼓励程序员去将数据分开地存放在一个个堆分配空间中。这就意味着程序员无法控制数据存储方式了,也开始产生不必要的缓存未命中问题,而导致性能急速的下降。C# 已经支持原生编译 也不会提升太多性能——毕竟在内存不足的情况下,提高代码质量本就杯水车薪。
再加上存储是有开销的。在 64 位的机器上每个地址值占 8 位内存,而每次分配都会有存储元数据而产生的开销。与存储着少量大数据(以固定偏移的方式存储在其中)的堆相比,存储着大量小数据的堆(并且其中的数据到处都被引用)会产生更多的内存开销。尽管你可能不怎么关心内存怎么用,但事实上就是那些头部内容和地址信息导致堆变得臃肿,也就是在浪费缓存了,所以也造成了更多的缓存未命中,降低了代码性能。
当然有些时候也是有办法的,比如你可以使用一个很大的 List<T> 来构造数据池以存储分配你需要的数据和自己的结构体。这样你就可以方便的遍历或者批量更新你的数据池中的数据了。但这也会很混乱,因为无论你在哪要引用什么对象都要先能引用这个池,然后每次引用都需要做数组索引。从上文可以得出,在 C# 中做类似这样的处理的痛感比在 C++ 中做来的更痛,因为 C# 在设计时就是这样。此外,通过这种方式来访问池中的单个对象比直接将这个对象分配到内存来访问更加的昂贵——前者你得先访问池(这是个类)的地址,这意味着可能产生 2 次缓存未命中。你还可以通过复制 List<T> 的结构形式来避免更多的缓存未命中问题,但这就更难搞了。我就写过很多类似的代码,自然这样的代码只会水平很低而且容易出错。
最后,我想说我指出的问题不仅是那些“热门”的代码。惯用手段编写的 C# 代码倾向于几乎所有地方都用类和引用。意思就是在你的代码中会频率均匀地随机出现数百次的运算周期损耗,使得操作的损耗似乎降低了。这虽然也可以被找出来,但你优化了这问题后,这还是一个 均匀变慢 的程序。
垃圾回收
在读下文之前我会假设你已经知道为什么在许多用例中垃圾回收是影响性能问题的重要原因。播放动画时总是随机的暂停通常都是大家都不能接受的吧。我会继续解释为什么设计语言时还加剧了这个问题。
因为 C# 在处理变量上的一些局限性,它强烈不建议你去使用大内存块分配来存储很多里面是内置对象的变量(可能存在栈中),这就使得你必须使用很多分配在堆中的小型类对象。说白了就是内存分配越多会导致花在垃圾回收上的时间就越多。
有些测评说 C# 或者 Java 是怎么在一些特定的例子中打败 C++ 的,其实是因为内存分配器都基于一种吞吐还算不错的垃圾回收机制(廉价的分配,允许统一的释放分配)。然而,这些测试场景都太特殊了。想要使 C# 的程序的内存分配率变得和那些非常普通的 C++ 程序都能达到的一样就必须要耗费更大的精力来编写它,所以这种比较就像是拿一个高度优化的管理程序和一个最简单原生的程序相比较一样。当你花同样的精力来写一个 C++ 程序时,肯定比你用 C# 来写性能好的多。
我还是相信你可以写出一套适用于高性能低延迟的应用的垃圾回收机制的(比如维护一个增量的垃圾回收,每次消耗固定的时间来做回收),但这还是不够的,大部分的高级语言在设计时就没考虑程序启动时就会产生大量的垃圾,这将会是最大的问题。当你就像写 C 一样习惯的去少去在 C# 分配内存,垃圾回收在高性能应用中可能就不会暴露出很多的问题了。而就算你 真的 去实现了一个增量垃圾回收机制,这意味着你还可能需要为其做一个写屏障——这就相当于又消耗了一些性能了。
看看 .Net 库里那些基本类,内存分配几乎无处不在!我数了下,在 .Net 核心框架 中公共类比结构体的数量多出 19 倍之多,为了使用它们,你就得把这些东西全都弄到内存中去。就算是 .Net 框架的创造者们也无法抵抗设计语言时的警告啊!我都不知道怎么去统计了,使用基础类库时,你会很快意识到这不仅仅是值或对象的选择问题了,就算如此也还是 伴随 着超级多的内存分配。这一切都让你觉得分配内存好像很容易一样,其实怎么可能呢,没有内存分配你连一个整型值都没法输出!不说这个,就算你使用预分配的 StringBuilder,你要是不用标准库来分配内存,也还不是连个整型都存不住。你要这么问我那就挺蠢的了。
当然还不仅仅是标准库,其他的 C# 库也一样。就算是 Unity(一个 游戏引擎,可能能更多的关心平均性能问题)也会有一些全局返回已分配对象(或数组)的接口,或者强制调用时先将其分配内存再使用。举个例子,在一个 GameObject 中要使用 GetComponents 来调用一个数组,Unity 会强制地分配一个数组以便调用。就此而言,其实有许多的接口可以采用,但他们不选择,而去走常规路线来直接使用内存分配。写 Unity 的同胞们写的一手“好 C#”呀,但就是不那么高性能罢了。
结语
如果你在设计一门新的语言,拜托你可以考虑一下我提到的那些性能问题。在你创造出一款“足够聪明的编译器”之后这些都不是什么难题了。当然,没有垃圾回收器就要求类型安全很难。当然,没有一个规范的数据表示就创造一个垃圾回收器很难。当然,出现指向随机值的指针时难以去推出其作用域规则。当然,还有大把大把的问题摆在那里,然而解决了这些所有的问题,设计出来的语言就会是我们想的那样吗?那为什么这么多主要的语言都是在那些六十年代就已经被设计出的语言的基础上迭代的呢?
尽管你不能修复这些问题,但也许你可以尽可能的靠近?或者可以使用域类型(比如 Rust 语言)去保证其类型安全。或者也许可以考虑直接放弃“类型安全成本”去使用更多的运行时检查(如果这不会造成更多的缓存未命中的话,这其实没什么所谓。其实 C# 也有类似的东西,叫协变式数组,严格上讲是违背系统数据类型的,会导致一些运行时异常)。
如果你想在高性能场景中替代 C++,最基本的一点就是要考虑数据的存放布局和存储方式。
作者简介:
我叫 Sebastian Sylvan。我来自瑞典,目前居住在西雅图。我在微软工作,研究全息透镜。诚然我的观点仅代表本人,与微软公司无关。
我的博客以图像、编程语言、性能等内容为主。联系我请点击我的 Twitter 或 E-mail。
via: https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow
作者:Sebastian Sylvan 译者:kenxx 校对:wxy