摘要:这篇文章我们将对一些各种各样的博客的流行度相对于他们在谷歌上的排名进行一个分析。所有代码可以在 github 上找到。

想法来源
我一直在想,各种各样的博客每天到底都有多少页面浏览量,以及在博客阅读受众中最受欢迎的是什么编程语言。我也很感兴趣的是,它们在谷歌的网站排名是否与它们的受欢迎程度直接相关。
为了回答这些问题,我决定做一个 Scrapy 项目,它将收集一些数据,然后对所获得的信息执行特定的数据分析和数据可视化。
第一部分:Scrapy
我们将使用 Scrapy 为我们的工作,因为它为抓取和对该请求处理后的反馈进行管理提供了干净和健壮的框架。我们还将使用 Splash 来解析需要处理的 Javascript 页面。Splash 使用自己的 Web 服务器充当代理,并处理 Javascript 响应,然后再将其重定向到我们的爬虫进程。
我这里没有描述 Scrapy 的设置,也没有描述 Splash 的集成。你可以在这里找到 Scrapy 的示例,而这里还有 Scrapy+Splash 指南。
获得相关的博客
第一步显然是获取数据。我们需要关于编程博客的谷歌搜索结果。你看,如果我们开始仅仅用谷歌自己来搜索,比如说查询 “Python”,除了博客,我们还会得到很多其它的东西。我们需要的是做一些过滤,只留下特定的博客。幸运的是,有一种叫做 Google 自定义搜索引擎(CSE)的东西,它能做到这一点。还有一个网站 www.blogsearchengine.org,它正好可以满足我们需要,它会将用户请求委托给 CSE,这样我们就可以查看它的查询并重复利用它们。
所以,我们要做的是到 www.blogsearchengine.org 网站,搜索 “python”,并在一侧打开 Chrome 开发者工具中的网络标签页。这截图是我们将要看到的:
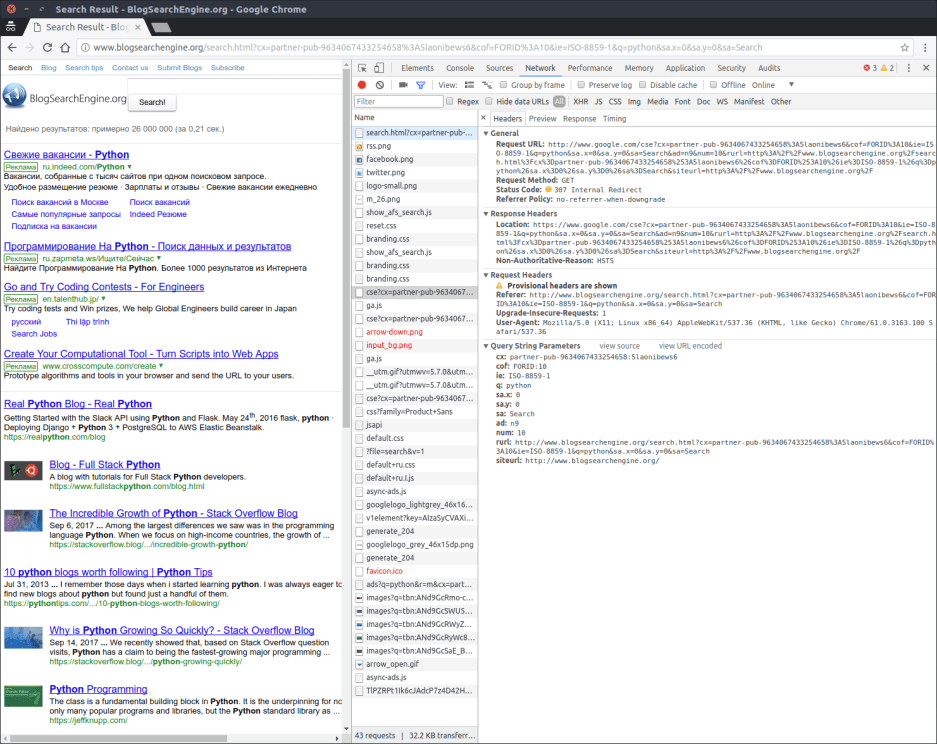
突出显示的是 blogsearchengine 向谷歌委派的一个搜索请求,所以我们将复制它,并在我们的 scraper 中使用。
这个博客抓取爬行器类会是如下这样的:
1
2
3
4
5
6
7
8
| class BlogsSpider(scrapy.Spider):
name = 'blogs'
allowed_domains = ['cse.google.com']
def __init__(self, queries):
super(BlogsSpider, self).__init__()
self.queries = queries
|
与典型的 Scrapy 爬虫不同,我们的方法覆盖了 __init__ 方法,它接受额外的参数 queries,它指定了我们想要执行的查询列表。
现在,最重要的部分是构建和执行这个实际的查询。这个过程放在 start_requests 爬虫的方法里面执行,我们愉快地覆盖它:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| def start_requests(self):
params_dict = {
'cx': ['partner-pub-9634067433254658:5laonibews6'],
'cof': ['FORID:10'],
'ie': ['ISO-8859-1'],
'q': ['query'],
'sa.x': ['0'],
'sa.y': ['0'],
'sa': ['Search'],
'ad': ['n9'],
'num': ['10'],
'rurl': [
'http://www.blogsearchengine.org/search.html?cx=partner-pub'
'-9634067433254658%3A5laonibews6&cof=FORID%3A10&ie=ISO-8859-1&'
'q=query&sa.x=0&sa.y=0&sa=Search'
],
'siteurl': ['http://www.blogsearchengine.org/']
}
params = urllib.parse.urlencode(params_dict, doseq=True)
url_template = urllib.parse.urlunparse(
['https', self.allowed_domains[0], '/cse',
'', params, 'gsc.tab=0&gsc.q=query&gsc.page=page_num'])
for query in self.queries:
for page_num in range(1, 11):
url = url_template.replace('query', urllib.parse.quote(query))
url = url.replace('page_num', str(page_num))
yield SplashRequest(url, self.parse, endpoint='render.html',
args={'wait': 0.5})
|
在这里你可以看到相当复杂的 params_dict 字典,它控制所有我们之前找到的 Google CSE URL 的参数。然后我们准备好 url_template 里的一切,除了已经填好的查询和页码。我们对每种编程语言请求 10 页,每一页包含 10 个链接,所以是每种语言有 100 个不同的博客用来分析。
在 42-43 行,我使用一个特殊的类 SplashRequest 来代替 Scrapy 自带的 Request 类。它封装了 Splash 库内部的重定向逻辑,所以我们无需为此担心。十分整洁。
最后,这是解析程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| def parse(self, response):
urls = response.css('div.gs-title.gsc-table-cell-thumbnail') \
.xpath('./a/@href').extract()
gsc_fragment = urllib.parse.urlparse(response.url).fragment
fragment_dict = urllib.parse.parse_qs(gsc_fragment)
page_num = int(fragment_dict['gsc.page'][0])
query = fragment_dict['gsc.q'][0]
page_size = len(urls)
for i, url in enumerate(urls):
parsed_url = urllib.parse.urlparse(url)
rank = (page_num - 1) * page_size + i
yield {
'rank': rank,
'url': parsed_url.netloc,
'query': query
}
|
所有 Scraper 的核心和灵魂就是解析器逻辑。可以有多种方法来理解响应页面的结构并构建 XPath 查询字符串。您可以使用 Scrapy shell 尝试并随时调整你的 XPath 查询,而不用运行爬虫。不过我更喜欢可视化的方法。它需要再次用到谷歌 Chrome 开发人员控制台。只需右键单击你想要用在你的爬虫里的元素,然后按下 Inspect。它将打开控制台,并定位到你指定位置的 HTML 源代码。在本例中,我们想要得到实际的搜索结果链接。他们的源代码定位是这样的:
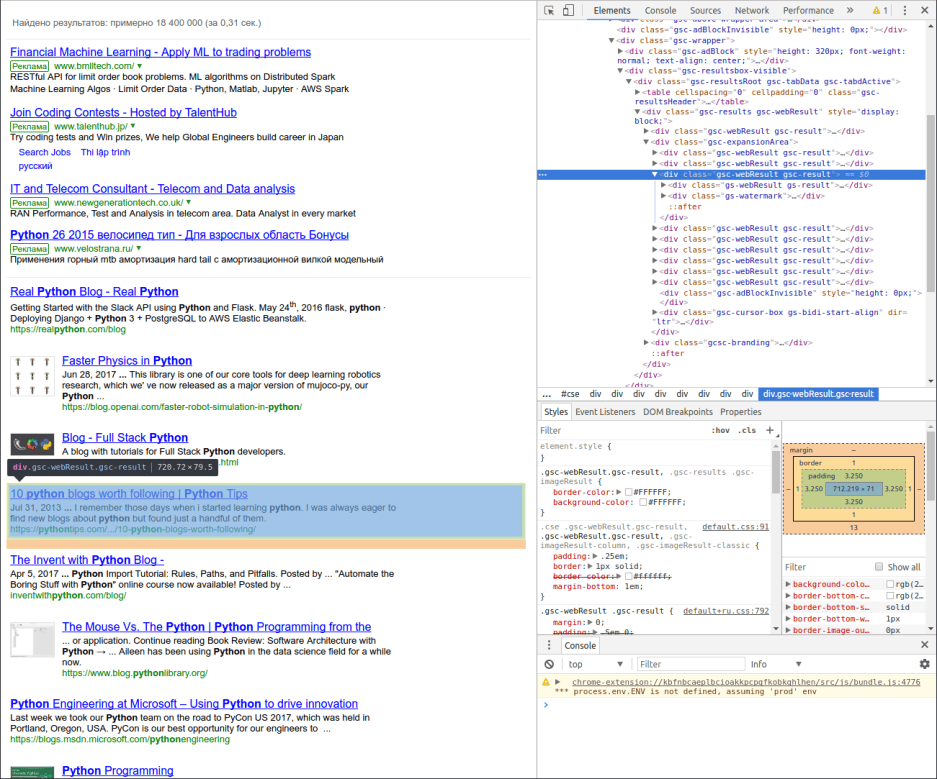
在查看这个元素的描述后我们看到所找的 <div> 有一个 .gsc-table-cell-thumbnail CSS 类,它是 .gs-title <div> 的子元素,所以我们把它放到响应对象的 css 方法(46 行)。然后,我们只需要得到博客文章的 URL。它很容易通过'./a/@href' XPath 字符串来获得,它能从我们的 <div> 直接子元素的 href 属性找到。(LCTT 译注:此处图文对不上)
寻找流量数据
下一个任务是估测每个博客每天得到的页面浏览量。得到这样的数据有各种方式,有免费的,也有付费的。在快速搜索之后,我决定基于简单且免费的原因使用网站 www.statshow.com 来做。爬虫将抓取这个网站,我们在前一步获得的博客的 URL 将作为这个网站的输入参数,获得它们的流量信息。爬虫的初始化是这样的:
1
2
3
4
5
6
7
8
| class TrafficSpider(scrapy.Spider):
name = 'traffic'
allowed_domains = ['www.statshow.com']
def __init__(self, blogs_data):
super(TrafficSpider, self).__init__()
self.blogs_data = blogs_data
|
blogs_data 应该是以下格式的词典列表:{"rank": 70, "url": "www.stat.washington.edu", "query": "Python"}。
请求构建函数如下:
1
2
3
4
5
6
7
8
9
| def start_requests(self):
url_template = urllib.parse.urlunparse(
['http', self.allowed_domains[0], '/www/{path}', '', '', ''])
for blog in self.blogs_data:
url = url_template.format(path=blog['url'])
request = SplashRequest(url, endpoint='render.html',
args={'wait': 0.5}, meta={'blog': blog})
yield request
|
它相当的简单,我们只是把字符串 /www/web-site-url/ 添加到 'www.statshow.com' URL 中。
现在让我们看一下语法解析器是什么样子的:
1
2
3
4
5
6
7
8
9
10
11
12
| def parse(self, response):
site_data = response.xpath('//div[@id="box_1"]/span/text()').extract()
views_data = list(filter(lambda r: '$' not in r, site_data))
if views_data:
blog_data = response.meta.get('blog')
traffic_data = {
'daily_page_views': int(views_data[0].translate({ord(','): None})),
'daily_visitors': int(views_data[1].translate({ord(','): None}))
}
blog_data.update(traffic_data)
yield blog_data
|
与博客解析程序类似,我们只是通过 StatShow 示例的返回页面,然后找到包含每日页面浏览量和每日访问者的元素。这两个参数都确定了网站的受欢迎程度,对于我们的分析只需要使用页面浏览量即可 。
第二部分:分析
这部分是分析我们搜集到的所有数据。然后,我们用名为 Bokeh 的库来可视化准备好的数据集。我在这里没有给出运行器和可视化的代码,但是它可以在 GitHub repo 中找到,包括你在这篇文章中看到的和其他一切东西。
最初的结果集含有少许偏离过大的数据,(如 google.com、linkedin.com、Oracle.com 等)。它们显然不应该被考虑。即使其中有些有博客,它们也不是针对特定语言的。这就是为什么我们基于这个 StackOverflow 回答 中所建议的方法来过滤异常值。
语言流行度比较
首先,让我们对所有的语言进行直接的比较,看看哪一种语言在前 100 个博客中有最多的浏览量。
这是能进行这个任务的函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| def get_languages_popularity(data):
query_sorted_data = sorted(data, key=itemgetter('query'))
result = {'languages': [], 'views': []}
popularity = []
for k, group in groupby(query_sorted_data, key=itemgetter('query')):
group = list(group)
daily_page_views = map(lambda r: int(r['daily_page_views']), group)
total_page_views = sum(daily_page_views)
popularity.append((group[0]['query'], total_page_views))
sorted_popularity = sorted(popularity, key=itemgetter(1), reverse=True)
languages, views = zip(*sorted_popularity)
result['languages'] = languages
result['views'] = views
return result
|
在这里,我们首先按语言(词典中的关键字“query”)来分组我们的数据,然后使用 python 的 groupby 函数,这是一个从 SQL 中借来的奇妙函数,从我们的数据列表中生成一组条目,每个条目都表示一些编程语言。然后,在第 14 行我们计算每一种语言的总页面浏览量,然后添加 ('Language', rank) 形式的元组到 popularity 列表中。在循环之后,我们根据总浏览量对流行度数据进行排序,并将这些元组展开到两个单独的列表中,然后在 result 变量中返回它们。
最初的数据集有很大的偏差。我检查了到底发生了什么,并意识到如果我在 blogsearchengine.org 上查询“C”,我就会得到很多无关的链接,其中包含了 “C” 的字母。因此,我必须将 C 排除在分析之外。这种情况几乎不会在 “R” 和其他类似 C 的名称中出现:“C++”、“C”。
因此,如果我们将 C 从考虑中移除并查看其他语言,我们可以看到如下图:
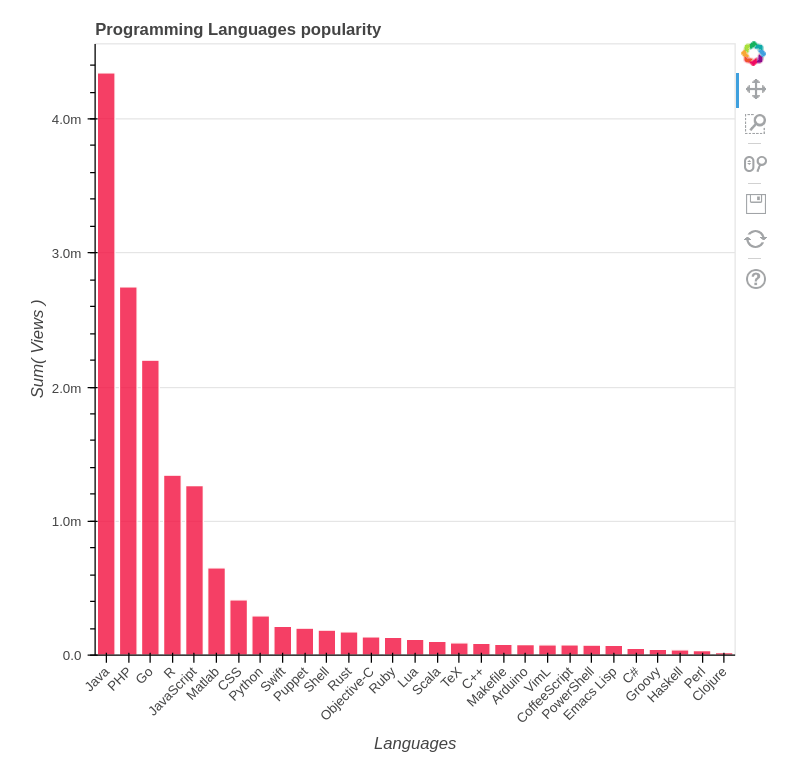
评估结论:Java 每天有超过 400 万的浏览量,PHP 和 Go 有超过 200 万,R 和 JavaScript 也突破了百万大关。
每日网页浏览量与谷歌排名
现在让我们来看看每日访问量和谷歌的博客排名之间的联系。从逻辑上来说,不那么受欢迎的博客应该排名靠后,但这并没那么简单,因为其他因素也会影响排名,例如,如果在人气较低的博客上的文章更新一些,那么它很可能会首先出现。
数据准备工作以下列方式进行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| def get_languages_popularity(data):
query_sorted_data = sorted(data, key=itemgetter('query'))
result = {'languages': [], 'views': []}
popularity = []
for k, group in groupby(query_sorted_data, key=itemgetter('query')):
group = list(group)
daily_page_views = map(lambda r: int(r['daily_page_views']), group)
total_page_views = sum(daily_page_views)
popularity.append((group[0]['query'], total_page_views))
sorted_popularity = sorted(popularity, key=itemgetter(1), reverse=True)
languages, views = zip(*sorted_popularity)
result['languages'] = languages
result['views'] = views
return result
|
该函数接受爬取到的数据和需要考虑的语言列表。我们对这些数据以语言的流行程度进行排序。后来,在类似的语言分组循环中,我们构建了 (rank, views_number) 元组(从 1 开始的排名)被转换为 2 个单独的列表。然后将这一对列表写入到生成的字典中。
前 8 位 GitHub 语言(除了 C)是如下这些:
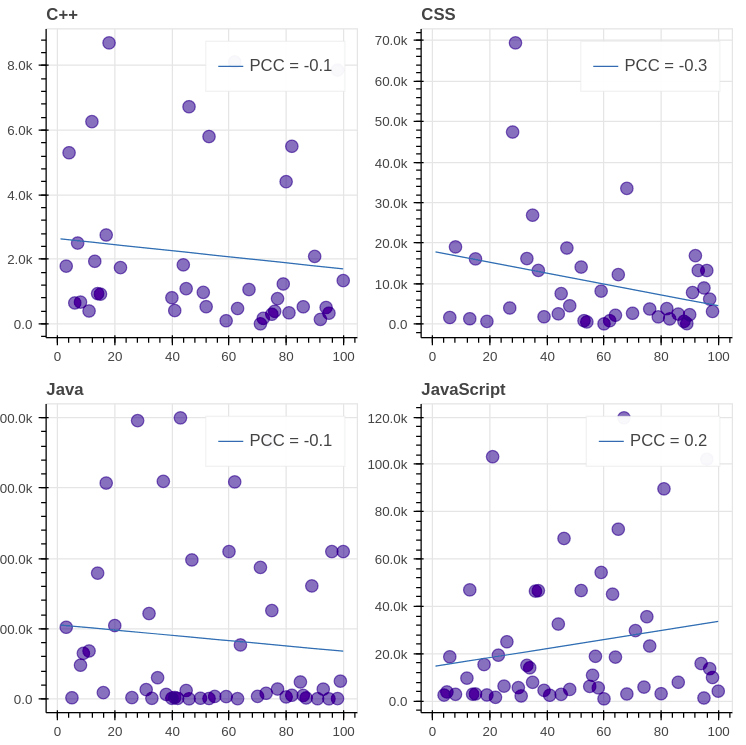
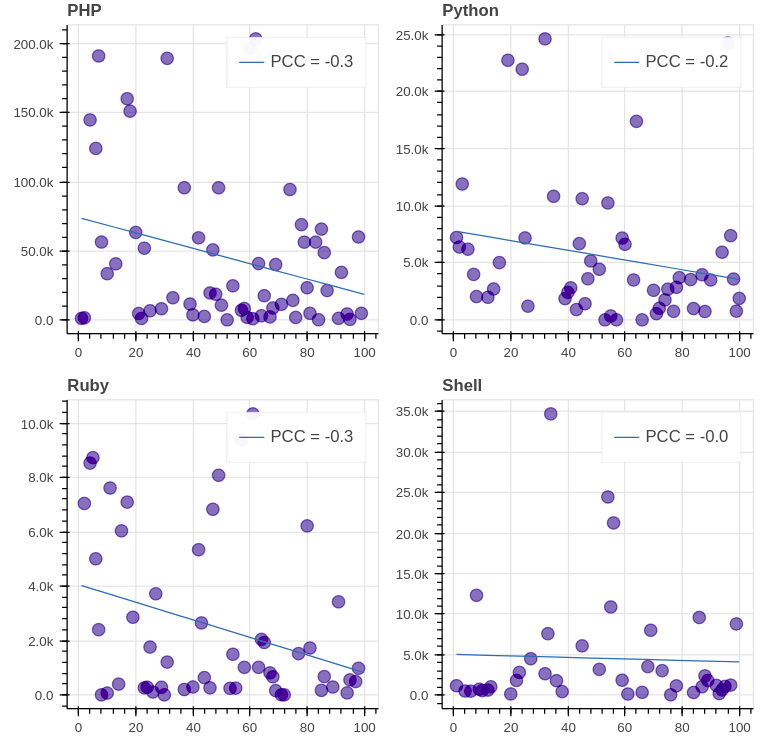
评估结论:我们看到,所有图的 PCC (皮尔逊相关系数)都远离 1/-1,这表示每日浏览量与排名之间缺乏相关性。值得注意的是,在大多数图表(8 个中的 7 个)中,相关性是负的,这意味着排名的降低会导致浏览量的减少。
结论
因此,根据我们的分析,Java 是目前最流行的编程语言,其次是 PHP、Go、R 和 JavaScript。在日常浏览量和谷歌排名上,排名前 8 的语言都没有很强的相关性,所以即使你刚刚开始写博客,你也可以在搜索结果中获得很高的评价。不过,成为热门博客究竟需要什么,可以留待下次讨论。
这些结果是相当有偏差的,如果没有更多的分析,就不能过分的考虑这些结果。首先,在较长的一段时间内收集更多的流量信息,然后分析每日浏览量和排名的平均值(中值)值是一个好主意。也许我以后还会再回来讨论这个。
引用
- 抓取:
- blog.scrapinghub.com: Handling Javascript In Scrapy With Splash
- BlogSearchEngine.org
- twingly.com: Twingly Real-Time Blog Search
- searchblogspot.com: finding blogs on blogspot platform
- 流量评估:
- labnol.org: Find Out How Much Traffic a Website Gets
- quora.com: What are the best free tools that estimate visitor traffic…
- StatShow.com: The Stats Maker
via: https://www.databrawl.com/2017/10/08/blog-analysis/
作者:Serge Mosin 译者:Chao-zhi 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出