为初学者提供的 uniq 命令教程及示例

如果你主要是在命令行上工作,并且每天处理大量的文本文件,那么你应该了解下 uniq 命令。该命令会帮助你轻松地从文件中找到重复的行。它不仅用于查找重复项,而且我们还可以使用它来删除重复项,显示重复项的出现次数,只显示重复的行,只显示唯一的行等。由于 uniq 命令是 GNU coreutils 包的一部分,所以它预装在大多数 Linux 发行版中,让我们不需要费心安装。来看一些实际的例子。
请注意,除非重复行是相邻的,否则 uniq 不会删除它们。因此,你可能需要先对它们进行排序,或将排序命令与 uniq 组合以获得结果。让我给你看一些例子。
首先,让我们创建一个带有一些重复行的文件:
1 | |
1 | |
正如你在上面的文件中看到的,我们有一些重复的行(第一行和第二行,第三行和第五行是重复的)。
1、 使用 uniq 命令删除文件中的连续重复行
如果你在不使用任何参数的情况下使用 uniq 命令,它将删除所有连续的重复行,只显示唯一的行。
1 | |
示例输出:
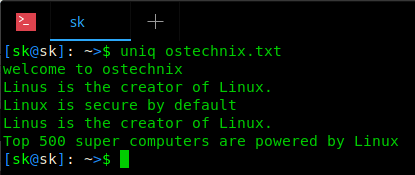
如你所见, uniq 命令删除了给定文件中的所有连续重复行。你可能还注意到,上面的输出仍然有第二行和第四行重复了。这是因为 uniq 命令只有在相邻的情况下才会删除重复的行,当然,我们也可以删除非连续的重复行。请看下面的第二个例子。
2、 删除所有重复的行
1 | |
示例输出:
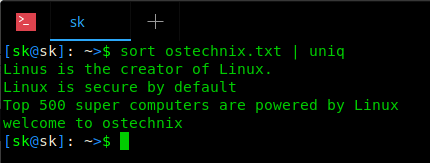
看到了吗?没有重复的行。换句话说,上面的命令将显示在 ostechnix.txt 中只出现一次的行。我们使用 sort 命令与 uniq 命令结合,因为,就像我提到的,除非重复行是相邻的,否则 uniq 不会删除它们。
3、 只显示文件中唯一的一行
为了只显示文件中唯一的一行,可以这样做:
1 | |
示例输出:
1 | |
如你所见,在给定的文件中只有两行是唯一的。
4、 只显示重复的行
同样的,我们也可以显示文件中重复的行,就像下面这样:
1 | |
示例输出:
1 | |
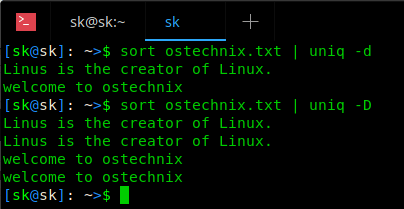
这两行在 ostechnix.txt 文件中是重复的行。请注意 -d(小写 d) 将会只打印重复的行,每组显示一个。打印所有重复的行,使用 -D(大写 D),如下所示:
1 | |
在下面的截图中看两个选项的区别:
5、 显示文件中每一行的出现次数
由于某种原因,你可能想要检查给定文件中每一行重复出现的次数。要做到这一点,使用 -c 选项,如下所示:
1 | |
示例输出:
1 | |
我们还可以按照每一行的出现次数进行排序,然后显示,如下所示:
1 | |
示例输出:
1 | |
6、 将比较限制为 N 个字符
我们可以使用 -w 选项来限制对文件中特定数量字符的比较。例如,让我们比较文件中的前四个字符,并显示重复行,如下所示:
1 | |
7、 忽略比较指定的 N 个字符
像对文件中行的前 N 个字符进行限制比较一样,我们也可以使用 -s 选项来忽略比较前 N 个字符。
下面的命令将忽略在文件中每行的前四个字符进行比较:
1 | |
为了忽略比较前 N 个字段(LCTT 译注:即前几列)而不是字符,在上面的命令中使用 -f 选项。
欲了解更多详情,请参考帮助部分:
1 | |
也可以使用 man 命令查看:
1 | |
今天就到这里!我希望你现在对 uniq 命令及其目的有一个基本的了解。如果你发现我们的指南有用,请在你的社交网络上分享,并继续支持我们。更多好东西要来了,请继续关注!
干杯!
via: https://www.ostechnix.com/uniq-command-tutorial-examples-beginners/